Cette revue est basée sur un ensemble de publications du mois de février 2023, issues de sources en lien avec le sujet Data. A piocher suivant vos centres d’intérêts.
Sommaire :
- La vie n’est pas un long fleuve tranquille pour les données : data depreciation, data drift, data integrity, untrustworthy data, biais in data, data reliability, data mistake, data breach, data paradox, data spoofing
- Catalogage et lineage des données : stewardship descriptif versus intégration et automatisation
- Enrichir le contexte de vos données
- L’intégration temps réel de données, le streaming data
- Support au sens des données : sémantique des données, mise en pictogramme des données, widgets data
- Data architecture – sujet récurrent : le Big Data est mort et la solution alternative est là, mais on a besoin de data engineer
- Data literacy
- Deux articles encore sur les tendances data 2023
- Pour finir quelques liens en vrac du mois : données synthétiques, référentiel bâtiment, capteurs, jumeaux numériques, open data
La vie n’est pas un long fleuve tranquille pour les données : data depreciation, data drift, data integrity, untrustworthy data, biais in data, data reliability, data mistake, data breach, data paradox, data spoofing …et quand le contexte d’interprétation des données les secoue.
Sur la dépréciation des données (cas des données personnelles) : la réglementation, les règles des entreprises du numérique (masquage de données de connexion, d’activité, des identifiants – publicitaires – cookies…), viser le 360° et les vues graphes (relier les appareils, les lieux, les personnes, à un foyer, à des proches…) devient trop cher, finalement comprendre le contexte est plus important que connaître le client (en se référant uniquement à ses données personnelles).
Dérives des données (data drift) et des concepts (concept drift) – formalisées dans l’application des modèles d’IA mais applicable plus largement à l’exercice d’interprétation des données : la représentativité d’un dataset change dans le temps (la répartition est impactée par des changements de contexte), la représentativité de comportements change avec un nouveau contexte (ex COVID). Source : https://www.dataversity.net/data-drift-vs-concept-drift-what-is-the-difference/
Intégrité des données : vue comme l’exactitude, la cohérence et l’intégrité référentielle entre N sources de données autour d’un objet, sources sur l’objet, mais aussi sur les contextes en jeu (exemple sur les données clients, événements, tendances de mode…). Source : https://www.precisely.com/blog/data-integrity/why-data-integrity-is-the-baseline-for-innovation
Méfiance sur les données utilisée : exemple sur la problématique de représentativité d’une population vis-à-vis d’autres (voir l’exemple de la communauté noire). Source : https://points.datasociety.net/black-health-and-data-expertise-building-trust-in-untrustworthy-data-abf46a8773d6
Biais sur les données et comment s’en préserver. Source : https://towardsdatascience.com/confronting-bias-in-data-is-still-difficult-and-necessary-e0982fd7416c
Fiabilité des données : 6 étapes à suivre. Source : https://towardsdatascience.com/6-steps-to-making-data-reliability-a-habit-521389b04aca?source=rss—-7f60cf5620c9—4
Erreur sur les données en B2B : méconnaissance de la collecte des données, non-respect de la légalité, non prise en compte de la dégradation des données dans le temps, ignorer la place dans le cycle d’achat où se trouve le client, ignorer le contexte.
Data breach … fuite de données, pas un jour sans ! Source : https://gizmodo.com/dna-testing-diagnostics-center-leaked-data-forgot-1850140233
5 paradoxes à connaître sur l’interprétation statistique de données : le paradoxe de précision (la précision n’est pas une bonne métrique pour classifier), le paradoxe du faux positif (sensibilité aux faux positifs – accroissement : négligence du taux de base sur les données de test), l’erreur du joueur (croire qu’un événement se produit plus souvent que sa fréquence normale), le paradoxe de Simpson (l’analyse de deux données, change lorsqu’on les agrège : assiette différente, non prise en compte de données de contexte différentes) et le paradoxe de Berkson (corrélation différente entre deux données suivant si on se place à un niveau agrégé ou dans un sous-ensemble). Source : https://www.kdnuggets.com/2023/02/5-statistical-paradoxes-data-scientists-know.html
Data spoofing (usurpation de données), cas des données d’identités –usurpation d’emails -> solutions pour s’en prémunir. NB : ce sujet est clé dans l’univers des données, comment s’assurer du bon attachement des données au bon objet ?
Catalogage et lineage des données : stewardship descriptif versus intégration et automatisation
La description des données et de leurs contextes de traitement (lineages) est indispensable. Maintenant comment maintenir cette description à jour ? L’exercice est sensible du fait de la masse de données, des évolutions permanentes des données. J’ai vu beaucoup de solutions via des outils de description maintenu à la main par un data steward, s’épuiser jusqu’à dans certain cas devenir un futur fantôme excel oublié après une opération de catalogage one shot (rôle fastidieux et ingrat de stewardship du catalogue, descriptions jamais à jour, si on se concentre sur les données transverses … la transversalité consomme trop d’énergie…).
L’autre façon, une sorte de graal, serait que ces descriptions soient automatisées, intégrées dans les supports et flux de données (le monde a changé, fini le mainframe pierre angulaire du S.I., mais quelle facilité pour ceux qui ont connus les développement mainframe – exemple Pacbase et le catalogue intégré !). Maintenant le revers de cette automatisation, c’est l’intégration. A minima toute nouvelle plate-forme de données devrait intégrer automatique la description de ses données.
Trois liens sur ce sujet vus en février :
1) Source : https://medium.com/startup-nation/top-5-benefits-of-automating-data-lineage-fd534591148d
Un lineage automatisé c’est :
- Un gain considérable dans la recherche des anomalies dans les chaînes de traitement, dans la réponse à des questions sur les données (avec l’élimination d’une grande partie de l’effort de retro-engineering vécu par tous ceux qui se sont frotté au sujet), exemple typique « Expliquez-moi ce chiffre !? »,
- La capacité à mettre sous contrôle les contraintes réglementaires sur les données dans les chaînes de traitement,
- Faciliter la gestion de la qualité des données,
- Apporter la connaissance nécessaire lorsqu’on veut faire évoluer les chaînes de traitements (analyse d’impact, changement de configuration, migrations…).
2) Source : https://www.dataversity.net/rwdg-slides-data-catalogs-are-the-answer-what-is-the-question/ Sur l’intégration voir ce que propose Alation (ici c’est le catalogue qui a la main, l’inverse serait préférable, c’est-à-dire la main aux plates-formes data) – 2 vues extraites :
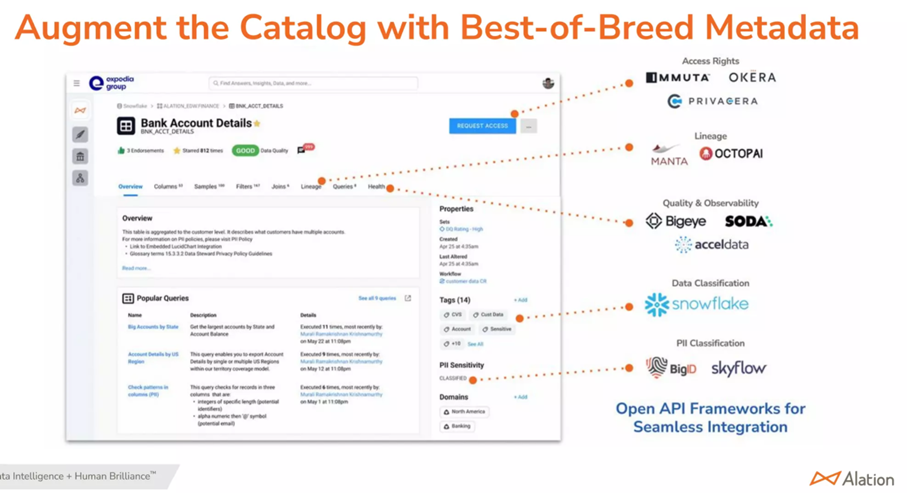
J’aime bien : les questions auxquelles doit répondre à un data catalog

Avec une réflexion intéressante chez Fivetran (https://www.fivetran.com/) sur la problématique d’intégration de la découverte des données, un inventaire complet data (les données, les métriques, les KPI, mais aussi les data products, le contexte : lineage, les usages par qui pour qui comment…) et le choix final d’une solution (à faible coût) en vision métier. Gérer toutes ces informations sur les données est lourd et complexe. La réflexion porte aussi à ne pas surcharger les acteurs par cette gestion. Le point de vue est métier, les solutions à la main de l’IT ont été éliminée (Collibra, Informatica, Alation et Data.World) pour finalement retenir la solution Select Star https://www.selectstar.com/ (le choix final ayant départagé ce choix avec la solution Atlan https://atlan.com/ ). NB la compatibilité avec le stack technique a été bien entendu l’un des critères (ici : BigQuery, Snowflake, Redshift, Looker et Tableau).
Enrichir le contexte de vos données
Le contexte des données est souvent oublié. Pourtant il joue un rôle clé dans l’interprétation des données.
Par contexte on entend principalement deux axes :
- Un axe de production de la donnée : lineage, comprendre comment elle est construite, comment elle a été produite à l’instant T, avec quelles règles, quelles conditions d’acquisition,
- Un axe connaissance : une donnée n’est jamais seule, elle fait partie d’un ensemble de données, elle est liée à un objet, elle s’inscrit dans un environnement (modélisé ou non).
Quelle est la capacité de réactivité à des événements, des changements de contexte, des piles de traitements des données ? Enrichissement en temps réel, réduction de l’influence de certaines sources de données… Source : https://www.precisely.com/blog/data-integrity/agile-data-stacks-to-enable-flexible-decision-making
Labellisation des données : interprétation du contexte pour décrire les données. En particulier en exploitant les données non structurées (documents, images, vidéo, réseaux sociaux…).La demande explose, le marché de la labellisation se développe à grande vitesse, comprendre les nuances contextuelles demande de plus en plus d’expertise, la pression temps réel s’accroit (avec des dérives … en dernière data OpenAI ChatGPT et l’emploi de travailleurs au Kenya sous-payés). Source : https://www.cogitotech.com/blog/data-labeling-2023/
L’intégration temps réel de données, le streaming data
C’est une tendance forte (a minima dans la communication sur les données ! NB : attention à ne pas reproduire l’effet Big Data … Netflix, Uber… ont besoin de cette gestion temps réel … mais vous ?) :
Solutions d’intégration de données chronologiques : revue des solutions d’ingestion (ETL Extract Transform Load, ELT Extract Load Transform, CDC Change Data Capture) et stockage dans les base de données timeseries. Source : https://towardsdatascience.com/data-integration-strategies-for-time-series-databases-f96cab274820
Analytique en temps réel : exemples et avantages Source : https://www.dataversity.net/real-time-analytics-examples-and-benefits/
Emergence de startups sur le domaine du streaming de données :
https://techcrunch.com/2023/02/08/streamdal-wants-to-bring-greater-visibility-to-streaming-data-architectures/ (Streamdal surveillance et analyse sémantique des flux : https://streamdal.com/ )
https://techcrunch.com/2023/02/13/influxdata-lands-51m-to-grow-its-time-series-database-offerings/ (Influxdata base de données temps réel : https://www.influxdata.com/ )
Tout sur le streaming de données : streaming versus traitement par lots, assemblage de flux, SLA. Source : https://chengzhizhao.com/streaming-data-is-exciting-what-you-need-to-know-before-taking-the-plunge/
Support au sens des données : sémantique des données, mise en pictogramme des données, widgets data
Quand DbtLab (https://www.getdbt.com/ solution d’analyse de données avec une levée de fond de 222 Millions de $) acquière la société Transform spécialiste des outils sémantiques https://transform.co/ ). Source : https://www.techtarget.com/searchbusinessanalytics/news/365530993/DBT-Labs-acquires-Transform-to-enhance-Semantic-Layer-tool
Sur l’idée de couche sémantiques voir aussi la compilation de liens de références faite ici : https://www.linkedin.com/posts/mehdilabassi_carrefourabrlinks-data-analytics-activity-7031669431294377984-X7_I/?utm_source=share&utm_medium=member_android
Voir aussi ce lien couche sémantique et data mesh – vu de Atscale https://www.atscale.com/ : https://www.dataversity.net/slides-how-a-semantic-layer-makes-data-mesh-work-at-scale/
Mise en pictogramme des données pour une meilleure lecture : l’article n’est pas très parlant … mais le sujet mérite l’attention (… les émotions ont bien été mises en émoticônes !). Source : https://www.smartdatacollective.com/how-pictographs-make-technical-data-more-user-friendly/
Widget data, comment en développer et les intégrer en python. NB : rejoint la famille des data products support de sens aux données. Les widgets sont intégrables en contexte (interface utilisateur), d’où leur intérêt pour l’interprétation de données. Source : https://towardsdatascience.com/making-your-data-analytics-come-to-life-using-ipywidgets-cfa9538279f7
Rappel définition d’un data product :
- L’origine : « To start, for me, a good definition of a data product is a product that facilitates an end goal through the use of data. Data Jujitsu – The art of turning data into product – DJ Patil – 2012 » https://www.oreilly.com/library/view/data-jujitsu-the/9781449342692/ch01.html#use_product_design
- Idée de solution à une problématique (décision, analyse, monitoring…) propulsée par les données. Derrière l’idée de data product, il y a l’idée de répondre à un objectif, un but, une finalité.
- Exemples : datasets verticaux et services d’accès-de consommation associés, charts-tableaux de bord-data visualisation, cubes analytiques, vues consolidées-360°, ciblage, couche sémantique APIisée… et certains poussent jusqu’à l’idée générale de tout système/produit dont les données sont cœur – exemple le calcul d’itinéraires[1] ou encore la voiture autonome vus comme un data product. [1] Le problème … tout algorithme vit à partir de données ! Un module d’IA peut être cité comme un data product.
Data architecture – sujet récurrent : le Big Data est mort et la solution alternative est là, mais on a besoin de data engineer
1) Le premier article est très intéressant et confirme les nombreux échecs Big Data, aveuglés par le buzz Big Data de l’époque…
Big data is dead : https://motherduck.com/blog/big-data-is-dead/
(voir aussi quelques remarques sur le sujet ici : voir https://www.datassence.fr/2023/02/13/quels-modeles-de-stockage-des-donnees-pour-en-tirer-quel-sens/)
2) Le second article reprend les déboires Big Data – extrait et traduction « Jetez tout ce que vous avez ici à l’intérieur et inquiétez-vous plus tard » … En théorie, il s’agissait simplement de tout jeter à l’intérieur de Hadoop et plus tard d’écrire des tâches pour traiter les données » et présente l’approche et l’utilisation (en python) de DeltaLake (https://delta.io/ ) de la famille des Data Lakehouse. Source : Source : https://towardsdatascience.com/hands-on-introduction-to-delta-lake-with-py-spark-b39460a4b1ae. Ou l’art de combiner le meilleur des data lake / big data (flexibilité) et des datawarehouse (contrôle).
3) Le troisième article propose une revue du métier de data engineer … le métier le plus recherché et le plus critique dans le monde des données. On le sait l’intégration des différentes briques d’architecture data EST le problème clé – la raison de nombreuses désillusions. La compétence d’intégration a toujours été critique , encore plus dans le monde des données au vu de toutes les facettes à prendre en compte (3V Big Data, sécurité, observabilité, SLA, data management, publication…) l’intégration (au sens génie logiciel) peut alors devenir le « pire cauchemar » de ce type de projet. Source : https://dataconomy.com/2023/02/how-data-engineers-tame-big-data/ data enginneer
Voir aussi en lien avec cette problématique d’intégration, l’idée de data visualisation-monitoring pour l’IT : source https://www.lebigdata.fr/grafana-visualisation-donnees et https://techcrunch.com/2023/02/08/data-observability-platform-acceldata-raises-50m/
Data literacy
Un état de l’art 2023 de la data literacy vu ici https://www.linkedin.com/feed/update/urn:li:activity:7034075732196638720/ par Datacamp (https://www.datacamp.com/ ) : https://res.cloudinary.com/dyd911kmh/image/upload/v1676480048/Marketing/Blog/The_State_of_Data_Literacy_2023.pdf. Etat de l’art naturellement orienté compétence et formation de par ses rédacteurs (Datacamp : spécialiste dans les formations data)
La culture de la donnée au travers du data journalism : https://dataculturegroup.org/2023/02/28/data-journalism-you-can-do-it.html
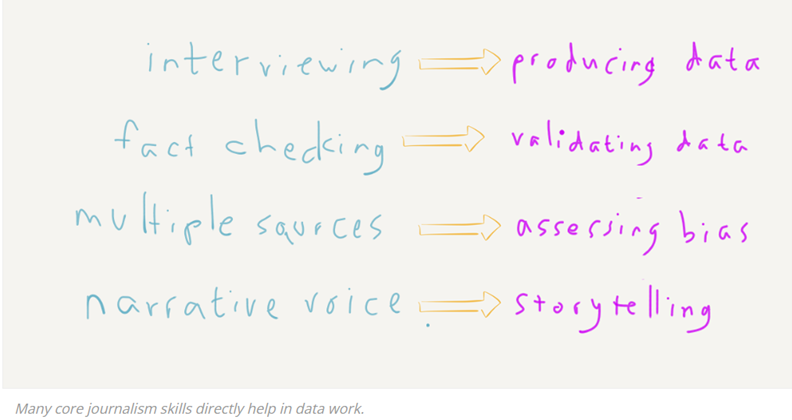
Deux articles encore sur les tendances data 2023
Data science trend 2023 https://www.dataversity.net/data-science-trends-in-2023/
Data buzz word 2023 https://towardsdatascience.com/data-buzzwords-you-need-to-know-in-2023-part-ii-42057a87814a
Pour finir quelques liens en vrac du mois : données synthétiques, référentiel bâtiment, capteurs, jumeaux numériques, open data
Données synthétiques :
https://www.kdnuggets.com/2023/02/5-reasons-need-synthetic-data.html
Circulation des données – réglementaire
Naissance d’un référentiel bâtiment
Capteurs : https://www.medgadget.com/2023/02/wearable-device-senses-when-vocal-fatigue-sets-in.html et https://www.presse-citron.net/quest-ce-que-ce-patch-qui-surveille-votre-voix/
Jumeaux numériques : https://www.journaldunet.com/web-tech/dictionnaire-de-l-iot/1489511-jumeau-numerique-l-afnor-cree-une-commission-dediee/
https://journals.sagepub.com/doi/full/10.1177/20539517231155061
Open data : https://www.opendatafrance.net/2023/02/21/donnees-et-transition-participez-a-lenquete-ecospheres/
RDV maintenant en avril pour la revue et les actualités de mars !
Les commentaires sont fermés.